
【エンジニア向け】KerasモデルでiPhoneで画像分類してみよう
ChatGPT等の生成系AIの登場により、ますます人の生活に密接になってきているAIですが、そのAIの頭脳とも言える機械学習モデルは、スペックの高いサーバマシンでのみ動作するものでは無く、今や殆どの方が持っているスマートフォンでも動作可能です。
ユーザはPCから各種サイトやサービスにアクセスする方は少なく、AI技術においても、ユーザを意識してスマートフォン向けにサービスを最適化させる事は非常に重要です。今回のコラムでは、画像分類を行う機械学習のモデルをユーザのスマートフォン(iOS)で動かす方法について取り上げたいと思います。画像分類モデルがユーザのスマートフォンでも動作するようになると、AIを使用したアプリケーションがより幅広い用途で使用可能になります。
Python(パイソン)、Swift(スウィフト)等のプログラミング言語の経験者や、機械学習のモデルの実装経験がある方等、エンジ二アを対象に、前半はPythonのKeras(ケラス)というライブラリを使用して、簡単な画像分類を行う機械学習モデルを実装し、後半はそれをiOSで動かしてみるという技術的な内容をお届けします。
一部コードサンプルを記載しておりますので、参考にしてください。
目次
前提条件
上述の通り、本記事はPython、Swift等の言語に経験があり、機械学習の基礎的な知識を既にお持ちの方に対しての記事となっているので、PythonやSwiftの文法の解説や、機械学習の仕組みに関する解説は行いません。
開発環境に関しても特に指定は無く、開発環境に関する皆さまが普段お使いの開発環境を指定してください。本記事では、開発環境のOSはMac OS、Pythonの統合環境はVSCode、Swiftの統合環境はXcodeと想定しています。
また、画像分類タスクに利用する画像などは各自収集をお願いいたします。
使用するライブラリ・フレームワークに関する知識
以下に本記事を読み進めて行くのにあたって、前提として把握しておいたほうが良い内容について解説をしておきます。
Keras(ケラス)とは
Kerasは、高水準のニューラルネットワークライブラリであり、Pythonで機械学習モデルを構築する際に使われます。元々は独立したライブラリとして存在していましたが、後にTensorFlowの一部として統合されました。Kerasは、ユーザーフレンドリーなAPIを提供し、複雑なネットワークアーキテクチャの構築からモデルのトレーニングまでを容易に行えるよう設計されています。
以下にKerasの特徴と利点をいくつか示します:
-
シンプルなインタフェース
Kerasは、シンプルで使いやすいインタフェースを提供します。高レベルの抽象化を使用して、複雑なニューラルネットワークの構築を少ないコードで行えます。
-
モジュール性
Kerasはモデルをレイヤーに分解し、それぞれのレイヤーを組み合わせてモデル全体を構築するモジュールアプローチを採用しています。これにより、ネットワークの構造を分かりやすく調整できます。
-
バックエンドの選択肢
Kerasは元々はTheanoという深層学習ライブラリをバックエンドとして使用していましたが、TensorFlowやMicrosoft Cognitive Toolkit(CNTK)などの他のバックエンドもサポートしています。ただし、TensorFlowをバックエンドとした統合版が最も一般的です。
-
豊富なプリトレーニング済みモデル
Kerasは、様々なアプリケーションに使用できるプリトレーニング済みのニューラルネットワークモデルを提供しています。これにより、転移学習や軽量なアプリケーション開発が容易になります。
-
カスタムレイヤーと損失関数
Kerasでは、独自のカスタムレイヤーや損失関数を簡単に定義して使用できます。これにより、特定の問題に合わせてモデルをカスタマイズできます。
Kerasは初心者からエキスパートまで幅広いユーザーに向けたライブラリであり、深層学習モデルを迅速に構築して実験するための優れたツールです。
CoreML(コアエムエル)とは
CoreMLは、Appleが開発したフレームワークであり、機械学習モデルをiOSやmacOSなどのAppleデバイス上で実行するためのツールセットです。CoreMLを使用することで、機械学習モデルをモバイルアプリやデスクトップアプリに統合し、リアルタイムの予測や分類を行うことができます。
CoreMLの特徴と機能について以下に説明します:
-
統合されたフレームワーク
CoreMLはAppleのエコシステムに統合されており、iOSアプリやmacOSアプリ内でシームレスに機械学習モデルを活用できます。
-
機械学習モデルの変換
CoreMLは、一般的な機械学習フレームワーク(例:TensorFlow、PyTorch)でトレーニングされたモデルをCoreML形式に変換するツールを提供します。これにより、トレーニング済みモデルをAppleデバイス上で直接実行できます。
-
高速な推論
CoreMLは、Appleのプロセッサ(例:Aシリーズチップ)に最適化されており、モデルの推論処理を高速に実行できます。モバイルアプリ内でリアルタイムの予測や分類を行う際に非常に有効です。
-
プライバシーとセキュリティ
CoreMLは、Appleのプライバシーとセキュリティ基準に準拠しています。ユーザーのデータはデバイス内で処理されるため、外部のサーバーにデータを送信することなくモデルを使用できます
-
VisionとNatural Language Processing(NLP)
CoreMLは、画像認識や自然言語処理などのタスクをサポートするために、VisionフレームワークとNatural Languageフレームワークと統合されています。これにより、画像分類やテキスト解析などのアプリを簡単に開発できます。
CoreMLは、アプリケーションに機械学習の力を組み込むための強力なツールであり、Appleデバイス上でのユーザーエクスペリエンスを向上させるのに役立ちます。
CoreMLのVisionフレームワークについて
CoreMLのVisionフレームワークは、Appleが提供するiOSやmacOS向けのフレームワークの一つで、機械学習とコンピュータビジョンのタスクをサポートするためのツールセットです。このフレームワークは、画像とビデオに対する高度な解析と処理を行うためのAPIを提供し、デバイス上でリアルタイムでの機械学習タスクを実行することができます。
具体的には、CoreMLのVisionフレームワークは以下のようなタスクに利用されます:
-
顔認識
顔の検出、識別、顔の特徴点の検出などの顔に関連するタスクを実行します。
-
物体認識
事前に学習されたモデルを使用して、物体や場所などを認識することができます。
-
テキスト検出
画像内のテキストを検出し、認識するための機能を提供します。
-
バーコード・QRコードの読み取り
画像内のバーコードやQRコードを検出して読み取ることができます。
CoreMLのVisionフレームワークは、機械学習モデルの展開や最適化、高速な推論のためのハードウェアアクセラレーションの活用など、多くの機能を提供します。また、開発者が独自のモデルを統合し、デバイス上で実行するためのインターフェースも提供しています。これにより、開発者は独自のアプリケーションに機械学習の機能を組み込むことが容易になります。
今回取り組む画像分類課題について
本記事のフォーカスは、Kerasで実装した画像分類モデルをiOSで動作させる事が目的なので、画像判別のタスク自体は非常にシンプルなタスクとしたいと思います。
具体的には、犬と猫の画像を判定する二値分類の問題とし、犬と猫の画像はこちらの記事などを参考にして、各自収集して頂ければと思います。
なお、あくまでこちらは画像分類のテーマの仮定にすぎないので、他の画像分類タスクを各自設定して取り組んで頂いても構いません。
Kerasによる画像分類コードの実装
それでは、犬と猫の二値分類の画像分類を行う、KerasのコードをPythonで実装していきます。
まずは、実装に必要なライブラリを以下のようにimportします。

次に画像に関する情報、及び、機械学習のパラメータに関して定義をしていきます。画像処理で使用する画像の大きさは 224 × 224とし、画像を事前にリサイズするように設定します。
それを元に学習モデルを実装するために、画像の前処理を行い、学習が行えるように調整します。
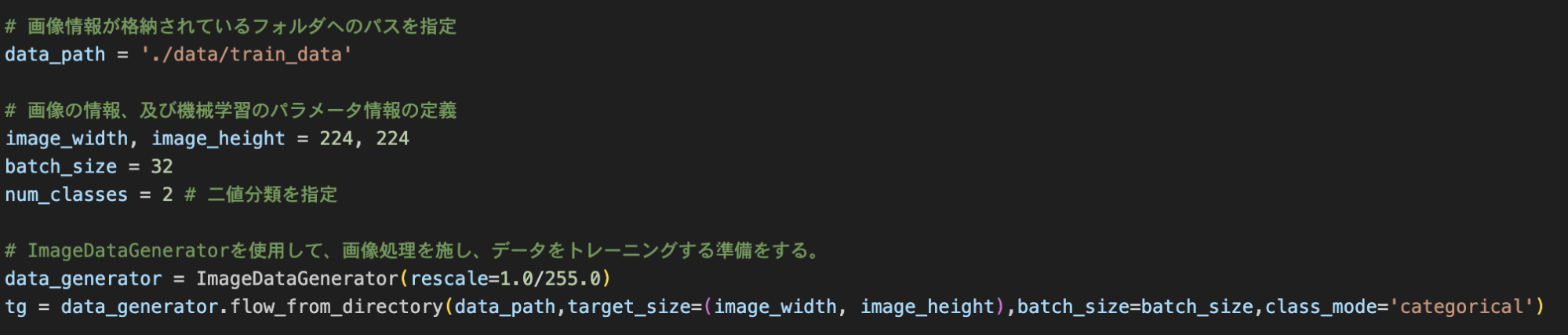
事前準備ができたら、Kerasを使用し、モデルの構築・コンパイルを経てモデルの学習を行います。最後に学習されたモデルを物理ファイルに保存しておきます。
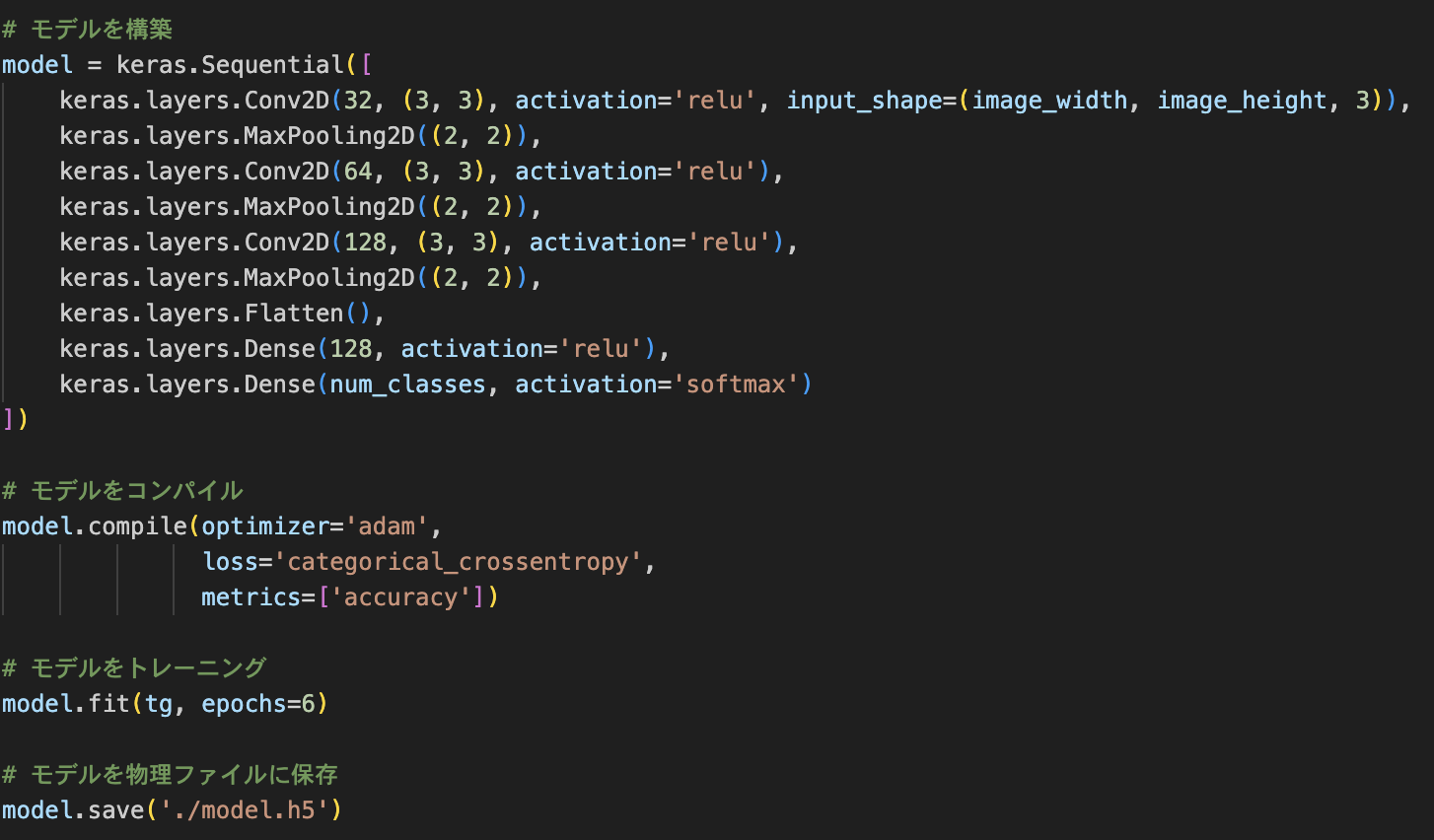
KerasモデルをCoreML用のモデルに変換する
通常はKerasで学習モデルを生成したら、それを使用して画像分類を行うPythonコードの解説を行うところですが、今回、画像分類はiOSで行う前提なので、そちらはSwiftでのタスクとなります。
それでは、Kerasで作成した画像分類モデルをSwiftで使用可能にするために、CoreMLで扱えるモデルに変換する必要があります。以下のコードがその変換を行うコードです。
これでKerasで実装した画像分類モデルをCoreMLで呼び出す事ができるようになりました。

SwiftでCoreMLモデルを使用する
それではKerasで実装した画像分類モデルをSwiftのCoreMLフレームワークで使用していきましょう。まずは、上述のKerasをCoreMLモデルに変換したモデル、「Test.mlmodel」がXcodeで正しく認識されるかどうか確認をしてみましょう。
以下のようにモデルがXcode上で認識されていたら、CoreMLでモデルが使用できる状態となっています。ここで大事な事は、Inputの項目がimageとなっていること、つまり入力として画像イメージを渡す事が可能になっているかどうかを確認する事です。もし、これが画像イメージが入力不可な場合は、CoreMLのVisionフレームワークの力を十分に発揮する事ができません。
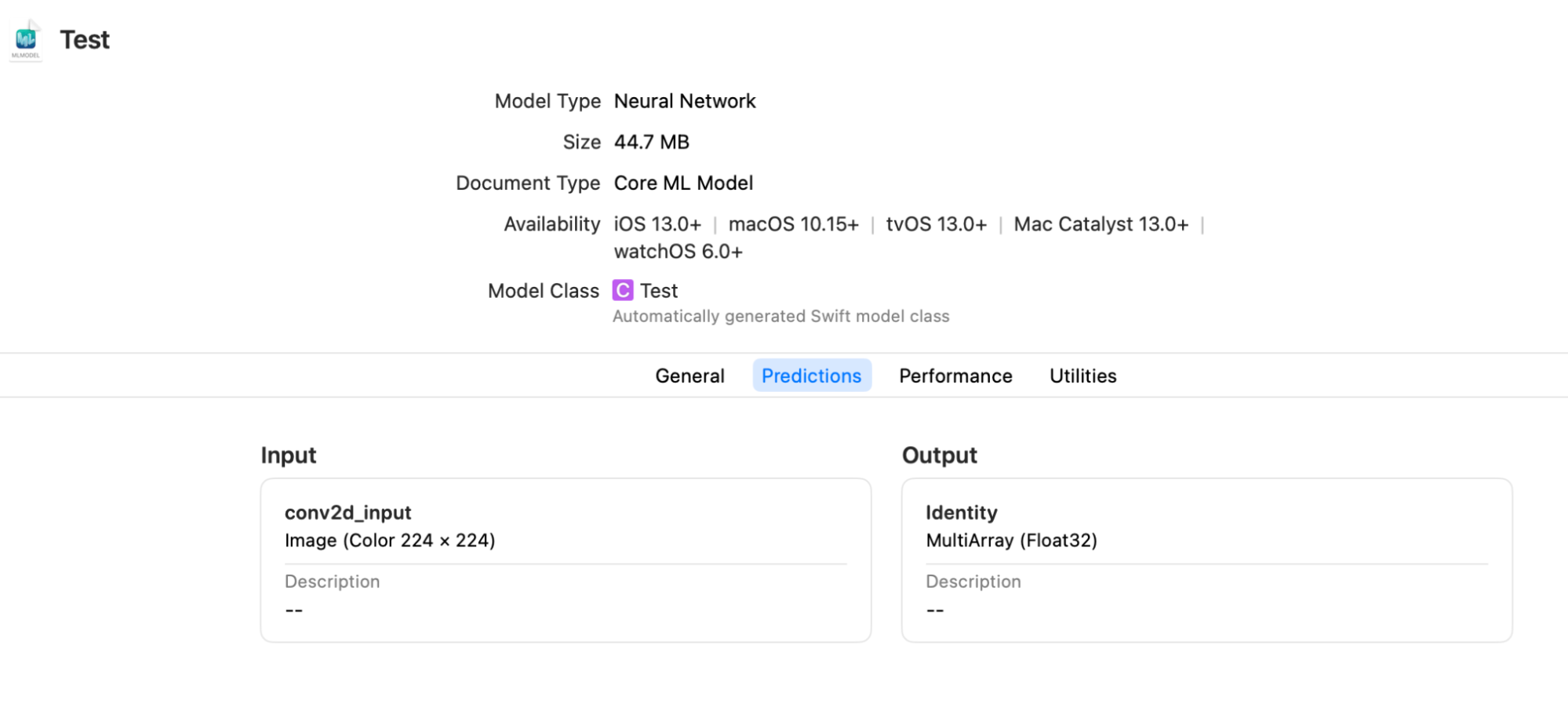
無事にモデルが認識されていたら、いよいよモデルを使用して、画像分類を行うコードの実装に進んでいきます。まずは、生成したモデルをCoreMLのVisionフレームワークで使用できるよう、以下のようなオペレーションを行います。
モデルのTestクラスは、上記の手順でXcodeで正しくモデルが認識されていれば、自動生成されているはずなので、それを使用します。ここで、先程記述した通り、認識されたモデルのinputがimageになっていなければ、Visionフレームワークのインスタンス(VNCoreMLModel )を取得する事ができず、この後の作業が非常に困難になってしまいます。

無事にVisionフレームワークのインスタンスを取得できたら、次はimageを入力して、画像分類結果を出力するコードの実装に進んでいきます。
入力として、244 × 244のサイズにリサイズされたUIImageを入力し、上記で取得したVisionフレームワークのインスタンスを使用し、画像分類を行うコードです。
最後のprintの部分で、結果が以下のような配列が出力されれば正しく動作しています。
[0.999999, 0.00001]
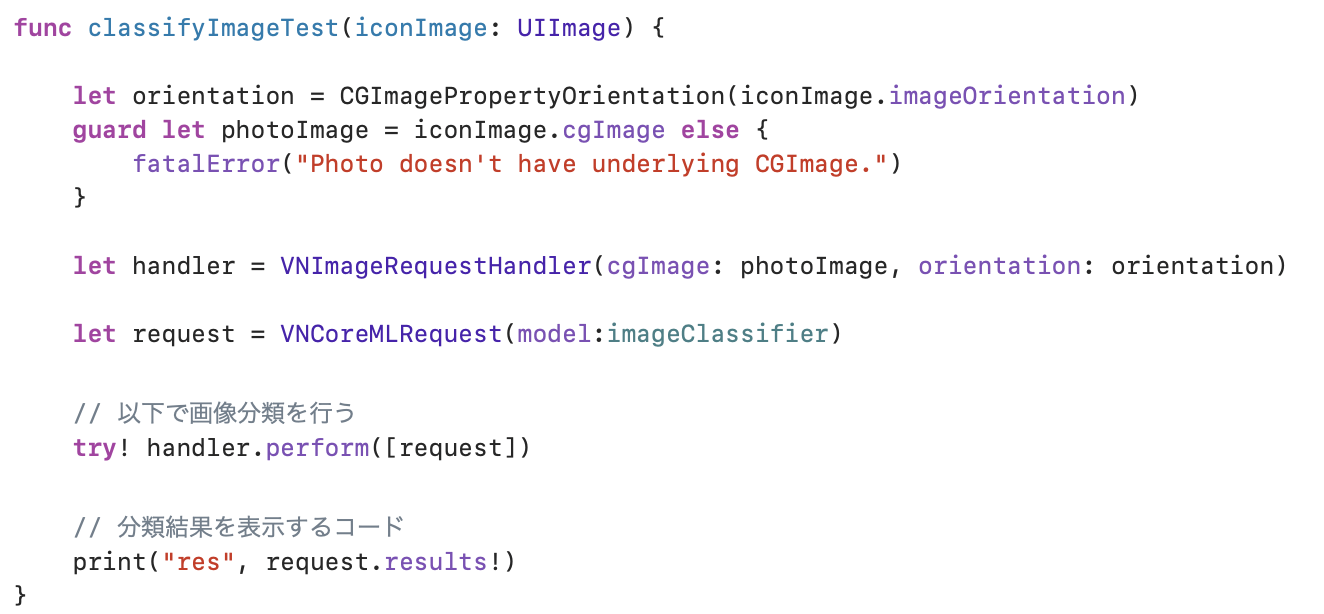
以下は、入力の画像をリサイズするためのコードです。前述の通り、ここでは244 × 244にリサイズをするために使用します。

最後に、上記の関数を呼び出すコードの例を示します。値は適宜、環境に応じて調整をされてください。

結論
今回は、Kerasによる画像分類モデルを、coreMLというフレームワークを使用して、iOSで動作をさせるまでの一連の流れについて解説を行いました。この方法を使用すれば、Pythonで作成した画像分類モデルをiOS上で実行する事が可能になり、スマートフォン上で幅広い使用用途で使う事が可能になります。
また、画像分類以外の機械学習モデルも同様の方法でスマートフォンで動作させる事が可能なので、AIのアプリケーション実装の幅が大きく広がる事になるので、本記事が皆さまのお役に立てれば何よりです。






